The "checkpoint not complete" messages are generated because the logs are switching so fast that the checkpoint associated with the log switch isn’t complete.
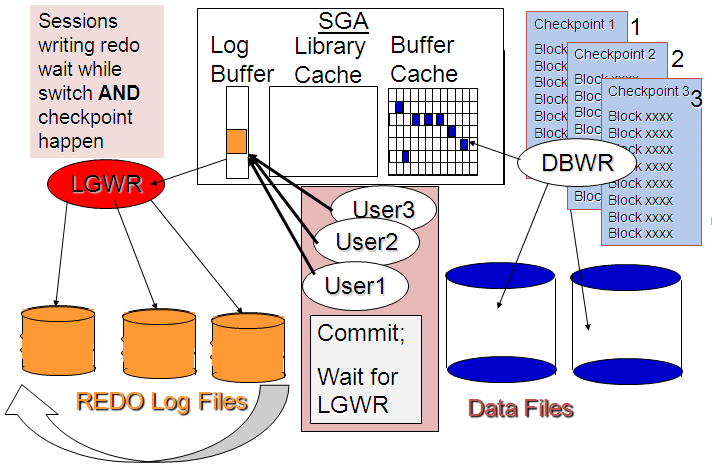
Oracle suggests that you
might consider setting archive_lag_target to zero to reduce
"checkpoint not complete" messages:
alter system set archive_lag_target=0 scope=both;
Overall Oracle performance
can be dramatically improved by increasing the log sizes so that
logs switch at the recommended interval of 15 to 30 minutes.
Identify the current size
of the redo log members from v$log, record the number of
log switches per hour and increase the size of the log to allow
Oracle to switch at the recommended rate of one switch per 15 to 30
minutes.
For example, if the database redo log size is 1
megabyte and you are switching logs every 1 minute, you will need to
increase the log size to 30 megabytes in size to allow it to switch
every 30 minutes.
You need to ensure that the on-line redo logs
don’t switch too often during periods of high activity and switch
often enough during times of low processing workloads.
This should reduce the delays from the checkpoint
not complete errors.
No comments:
Post a Comment